

Пример скрипта для скачивания больших файлов с гугл диска. Особенностью скачивания больших файлов является наличие дополнительного подтверждения для скачивания, гугл предупреждает что файл большой уточняет, точно ли его нужно скачать.
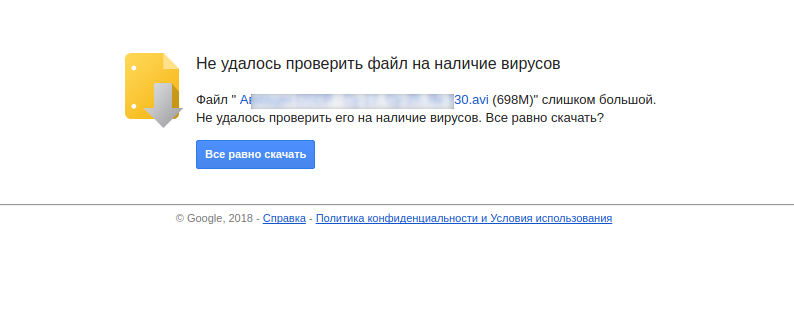
Скачать такое через wget, понятно, не получится.
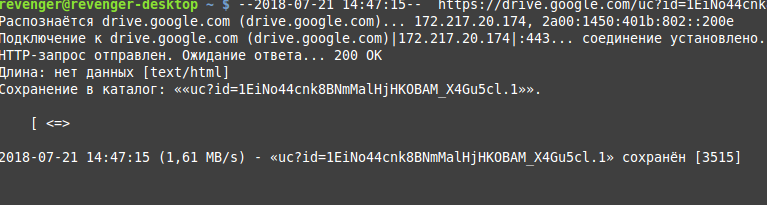
Скачивается html файл.
Чтобы скачать необходмый файл, нужен специальный скрипт с подзапросом. Первый запрос получает куки и сохраняет во временный файл. А уже вторым запросом с кукой получаем ссылку на файл.
Скачивание происходит по ID файла, вот откуда его взять:

ID подставляем в скрипт.
Заменить FILE_ID на вой и указать имя и расшрение сохраняемого файла.
И процесс пошел!